

Overview
Times change, seasons change, and worst of all from a maintenance standpoint - the underlying tech that supports our data pipelines change too.
It’s a tale as old as time. “We want to change out X in our pipeline tech stack. We need to do a migration!” Only for the project to be delayed or outsourced because it requires several engineers and too much time.
We’re in a new era. AI agents have suddenly become about as reliable as the contractors you may have outsourced the project to. Can we now live the AI-engineering dream and build out a harness so agents can do the work - gaining the improvements, but eliminating the internal and external costs of the migration?
The changing landscape
Middesk wanted to migrate some of the original core pipelines our business runs on. From a traditional ETL pipeline using Beam via Scio, a Spark-like mix of Scala and SQL, over to running closer to the metal in an ELT pipeline where we use our custom loading tools and then dbt to run the transforms in small incremental batches directly within our warehouse. This would be both a huge gain for us in time efficiency, while also increasing our observability, and reducing our cost and pipeline complexity.
This type of change is common in the data engineering world and traditionally requires large swaths of code changes with diligent validation so that no unintended consequences ensue. As data engineering veterans know, one of the worst outcomes is to ship data that slowly and insidiously shifts towards incorrect after a seemingly innocent change. For those of us who are truly old school, you may even remember validating these migrations when changing out the actual physical hardware on which our pipelines were running.
But now, there’s a new way to drive these migrations with agentic coding through harness engineering.
What is “harness engineering”?
Harness engineering is a rapidly evolving field, so what I’m writing today may be entirely out of date by tomorrow. But, right this moment, the concept of harness engineering refers to building out an environment in which coding agents can be left on their own. They may produce, test, iterate on, ship, and refine their code - all needing little to no regular human input.
In this context of our Middesk problem, I liken it to building a hamster wheel of AI agents to power our migration. Guides and tools are set up so that the hamster can keep on running without having to live in constant fear of our conversation with an agent exceeding the agents memory and context limitations...

If you’re interested in diving deeper into harness engineering, Birgitta Böckeler has a great write up here. This does a good job of breaking down OpenAI’s original proclamation that they’ve yet again changed the world of coding, and takes a scrutinizing look at what this new field entails from an unbiased standpoint.
Planning to build
So what would our harness engineering entail?
The majority of Middesk's upstream data sources don't have a well-defined data shape. Unlike commercial vendors, where schema changes are incremental and well-structured, most government and open sources deliver bulk data in formats that can change without notice. This creates an additional layer of complexity for our work. Therefore, our agent harness had to account for the instability of the raw data on the input side.
Because of this variability, before even starting this work, the team already had development tooling for humans to iterate on data pipelines effectively. We had tools to run our pipelines locally, CLIs to test out our configurations, as well as the ability to create our own development environments and run all of our pipelines against smaller datasets for quick iteration.
Before even starting the first candidate pipeline for this migration, we landed on our preferred feedback loop to build out the harness.
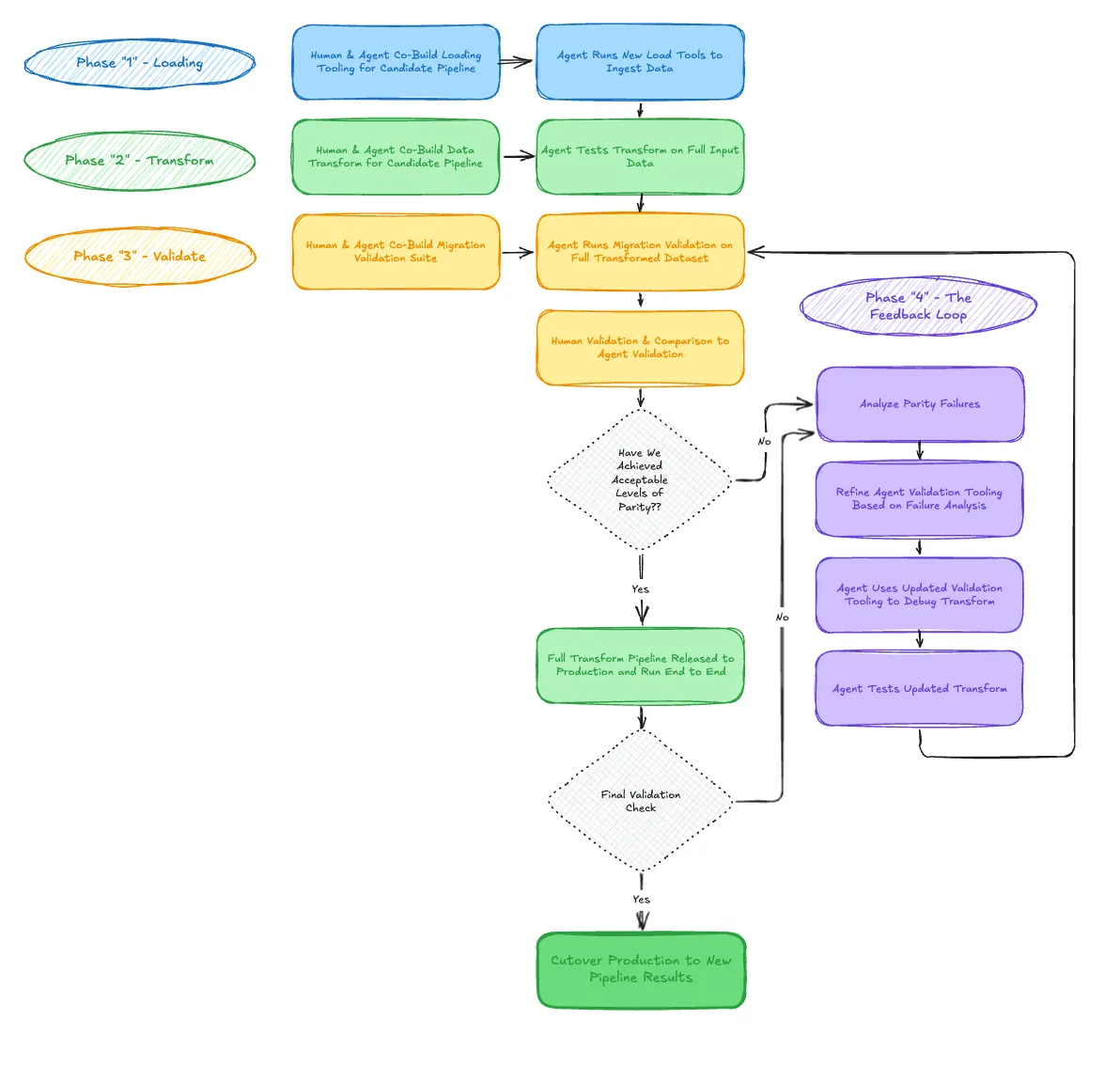
This feedback loop was focused around the transformation of the data. The loading is a more simple process that an agent equipped with basic validation scripts and queries could handle out of the box. We just had to build in coaching and set proper design patterns for our agents to follow.
The transformation was far more complex. The core feedback loop included:
- Let the agent do an initial pass on writing the data transformation.
- Let the agent run the data transformation.
- Assuming the transformation worked, let the agent validate the output in fashion similar to what previously a human would have done. This includes simple checks such as counting rows, to more complex checks like sampling individual records for equality, and even doing full set operations.
- If the agent didn’t do a perfect job on its first pass of the transformation, let the agent select a small handful of examples of where it went wrong, and coach the agent through identifying and fixing the bugs that resulted in the issue.
- Finally, and crucially, let the agent edit its own harness based on the analysis of what was missed, this could include writing out a new validation check, noting exceptions that it had missed, or even rewriting the initial prompts.
- Let the agent test drive the updated harness and attempt to modify the transformation again, do a final check, and then decommission the agent to move back to step 1.
When we finally achieved a data transformation that passed all the agent run checks, we moved on to a human doing manual validations. If the human found issues then we would go back to the beginning, but when things finally looked good - we shipped the migration pipeline.
How did it actually go?
The very first migration as we built out the harness felt so 2025. Human and agent, working together, problem by problem. Along the way, we let the agent document our work. Each road bump, the agent documented the problem and recorded what it tried and eventually used to successfully resolve the problem.
Progress was agonizing - inching forward at a pace likely slower than an established engineer working in the traditional way. However, the first tease of momentum started to show in our feedback loop. As our harness became established, we saw our agents require less prompting. We no longer needed to remind the agent of key details. The agents began to actually work.
Then, lift-off. We could feed in a single prompt, and the agent would go from a blank slate to a fully migrated pipeline that had been tested and validated in reasonable chunks, end to end.
This is an actual screen recording of an agent on roughly the tenth pipeline we had the agents handle migrating.
The first couple of migrations had a few hiccups, but by the time we picked up the fifth, sixth, and the seventh, the agents were able to immediately take off unsupervised. Soon the agents were able to complete multiple migrations in parallel and produce usable code on their first passes.
Progress took off. Linear’s calculation for projected completion time doesn’t account for exponential velocity increases… yet!
What this is and isn’t
A mini retrospective on harness engineering for data pipeline migrations for our data engineering colleagues.
What it isn’t yet:
- A fully autonomous set of agents that will do all our maintenance.
- A magical solution to coding agents making mistakes and fudging their numbers.
- The absolute latest and greatest version of what harness engineering can be.
But optimistically, this is what we accomplished:
- A set of prompts and guide rails that necessitated little to no re-prompting or re-directing from humans to migrate our pipelines.
- Re-usable success criteria for an agent to measure that its work on a pipeline did not change the output unexpectedly.
- An ability for two engineers to increase their output to rates previously unimaginable.
Takeaways
This kind of work is ideal for a swarm of coding agents. Agentic coding is rapidly evolving, but still in its early days. In this case, for the benefit of both the agents and ourselves, we started with something simple. For this project, the benefit of rote data engineering work is that it is easily checked and validated. At the end of the day, we still have a lot to learn. Our agents still have a lot to learn too. We recommend starting your journey into harness engineering by tackling similar types of tasks.
A key early learning is to ensure the feedback loop does not stop, it must be continual. The work each agent accomplishes can help refine the harness for the next agent. Every agent that works on this project, successful or not, leaves all its relevant learnings behind and can modify the guides and prompts to improve the next agent.
People have long debated the line between programming and software engineering — and now we get to have that same argument about vibe coders and engineers. Honestly, even when decisions are driven more by instinct than hard numbers, the goals are still the same ones we've always had: reusable components, simplicity, repeatability, idempotency. We can measure whether we're getting there. So let's write that down and actually use it.
Most importantly, no one wants to spend our time translating our logic - but the dream has come true and now we can actually have our cake and eat it too.


