

Overview
One of the most persistent challenges in building trust infrastructure at Middesk is what we call the data chicken-and-egg problem. Our pipelines are designed to scour primary sources like Secretary of State (SOS) offices and the IRS to construct high-fidelity business profiles. But when you are building a new feature or researching a complex edge case, finding a "real-world" example that fits your exact criteria can feel like searching for a needle in a haystack.
A business incorporated in Delaware, registered in California, with a UCC lien filed last month and a recent change in beneficial ownership? That profile exists in the real world. Finding it on demand, in a form that exercises the full pipeline, is a different problem entirely.
For a long time, our solution was a legacy sandbox that relied on "magic keywords." You would hard-code a specific string, and the system would return a pre-canned response. It was functional, but it was "flat." It bypassed the very pipelines we were trying to test and failed to mirror the entropy of the real world.
To address this, we've recently made powerful enhancements to the Middesk sandbox experience. The journey to fixing this didn't start with a formal roadmap item. It started at a company hackathon.
The hackathon vision: The 51st state
The idea began with a hackathon idea rather than through a traditional roadmap initiative: what if we didn't just mock the data, but simulated an entire world of it?
The initial vision was ambitious. We set out to build a complete digital government ecosystem — a simulated 51st state (“Silica”) populated with citizens and businesses conducting real financial activity. Virtual companies would apply for loans. Virtual lending institutions would use Middesk to profile them. Our scrapers could hit a simulated SOS website, find a registered entity, and pull that data through our entire processing pipeline. Less sandbox, more ant farm.
The pivot: From chaos to stability
We exposed the flaw in the approach quickly. The 51st State was too much of a simulation. It was chaotic, unpredictable, and, while technically interesting, it wasn't providing the stability a developer needs when debugging a specific pipeline failure. If you can't reproduce a scenario reliably, you can't debug it. And you can't build a testing culture around something you can't control.
We realized the sandbox needed to behave like a simulation while remaining fundamentally programmable.
We began to scale back the "digital state" and focus on Test Scenarios. Instead of simulating the entire ocean, we built the specific "containers" we needed. We shifted the focus to packaging state into dedicated, internal scenarios that the user has full control over. So in this world, instead of relying on a constantly changing simulation, the user tells us what the scenario is, and Middesk’s sandbox sets up all the records with all the correct data sources to reproduce that scenario. It still relies on a simulation, but this one is stable and predictable.
That realization turned a hackathon prototype into a real engineering investment.
Building for reproducibility
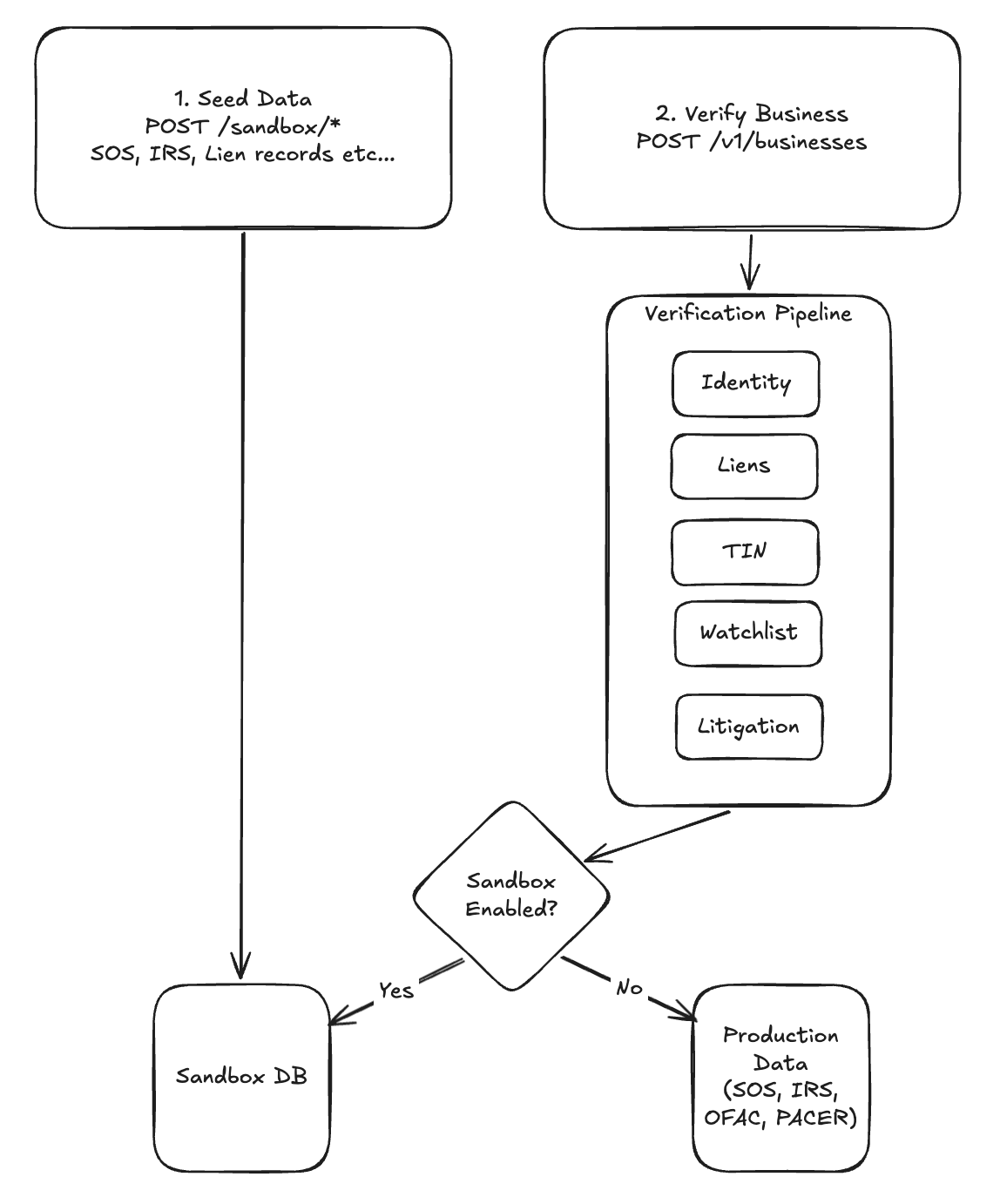
Here's how the Test Scenarios work. A developer specifies a scenario — the entity state, data source configuration, and the signals relevant to whatever they're testing. The sandbox provisions all the underlying records across data sources to match that specification. The result is a fully realized business profile that exercises the real pipeline, not a mock response layered on top of it. The data flows through the same processes it would in production. The outputs reflect what production would actually return.
Consider what this changes for a concrete case. Say you need to reproduce a scenario where a business was recently reinstated after a period of dormancy, with a new registered agent and an open UCC filing. In the old sandbox, getting there meant either finding a real business that matched those criteria or stitching together mock responses that bypassed most of the pipeline. With Test Scenarios, you declare the state you need and the sandbox constructs it. Every data source reflects the correct configuration, the pipeline runs as it would in production, and you see exactly what production would see.
That shift — from hoping a scenario appears to declaring it — changes more than just developer convenience. It changes what's testable. In the old model, edge cases required luck. You either found a real-world example or you didn't. In the new model, edge cases are deliberate. You define them, provision them, and test against them consistently. That's a meaningfully different standard of confidence.
Changing from the sprawling 51st State simulation to targeted Test Scenarios also resolved something the hackathon version never could: determinism. When a bug is reported in production, the first question is always whether you can reproduce it. With the old sandbox, the answer was often uncertain. With Test Scenarios, reproduction is straightforward — declare the state, run the pipeline, compare the output.
What we've learned from dogfooding it
We've been running the new sandbox environment internally for onboarding new engineers, testing new features, and reproducing production bugs. A few things have become clear.
New engineers understand the system faster when they can manipulate a realistic scenario than when they're decoding a canned response. The pipeline becomes legible when you can observe it processing something real — even if that something was constructed rather than found.
For feature development, what used to require waiting days for a matching production case to surface can now be provisioned in minutes. You can build for a scenario, test it, modify it, and test again without waiting for a production example to surface. That changes how confidently engineers ship.
And for bug reproduction, instead of starting from logs and guesswork, engineers now start from a reproducible state. That has made the debugging process substantially more systematic.
Why it matters
The 51st State was the right question asked at the right time. The answer we needed wasn't a simulated world — it was control over the world we were testing in.
What we built is an enhanced sandbox that behaves like the real system because it uses the real system, provisioned to a known state. The difference between that and a magic keyword returning a flat response is the difference between testing your pipeline and testing your mock.
Developers building on Middesk now have full control to test for their specific test cases when integrating Middesk into their applications. For the engineers maintaining the pipeline, it means confidence in what ships. And for the platform as a whole, it means the testing environment is finally as rigorous as the product it's meant to support.
Interested in building the data and ML systems that power trust for the business economy? Check out the open roles on the engineering team.


