

When we come up with important technical ideas, we spend time writing Requests for Comments (RFCs) to share them and solicit feedback from other Engineers. A good RFC states the problem, goals and non-goals, walks through options the author considered, has an opinion about the solution, and gives examples of how the solution will actually work.

Data is the core of Middesk, and we're always looking to improve our Extract, Load, and Transform process. I wrote an RFC recommending we enhance our transformation layer with dbt and wanted to share it here to give you all a sense of how we communicate prospective and important changes to Engineering here at Middesk.
Goals
The goal of this RFC is to propose a data transformation stack that allows everyone at Middesk to build and maintain robust and up-to-date, canonical datasets with the least amount of friction.
- It should require minimal effort to add new data sources.
- It should be catalogued - columns and tables should be annotated and documented.
- It should keep data up-to-date without interference.
- It should monitor and test data for faulty data or schema changes.
- It should alert us to potential problems once they are detected.
- It should be flexible - once issues are detected, updating the transformation of data should be easy.
- It should be visible - questions about update cadence and freshness should be easy to answer.
Non Goals
- Modify or adapt our Extract and Load processes.
Contributing factors
The ingestion and transformation of various data sources into one used by our internal products is often referred to as ETL (extract, transform, load) in the data world. There is a number of different configurations for a data stack to consider, which depends on the nature of the data and the consumers of the data.
Where our data comes from
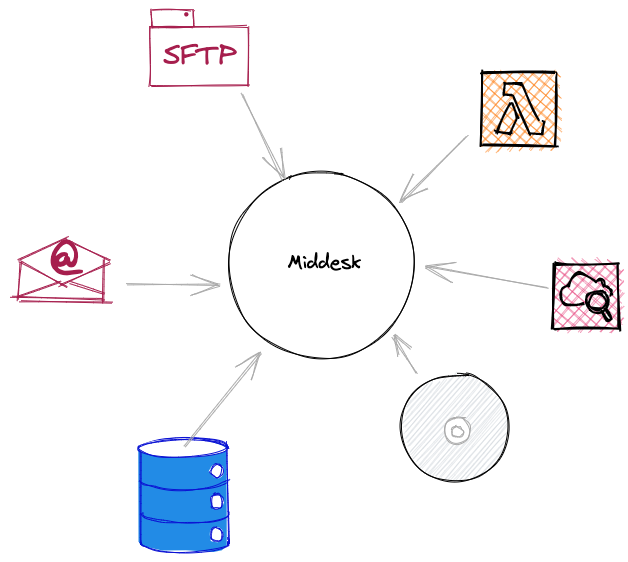
- State data is received from APIs, file transfers, manually transferred from Secretary of State websites by our Operations team, or manually received via email/CD (yep, really).
- Middesk production data that resides in PostgreSQL (we use Cloud SQL, a hosted solution from Google Cloud). This includes data such as businesses, accounts, webhooks, registrations associated with businesses, etc.
- Third party vendor data such as Segment and Front that report about the usage, customer communications, marketing efforts, etc of Middesk as a business.
What is our data like
At Middesk our data is in large part a collection of data sourced from government entities - registered businesses, filed liens, government watchlist entities, etc.
- There is a large variety of data formats: CSV, JSON, TSV, fixed-width, etc.
- The schema can change over time for a given dataset, there are no guarantees/SLAs.
- The data is usually not continuous - we receive data on a daily, weekly, monthly, or yearly cadence. There is usually not a stream of continuous data available.
- The data is retrieved from the source in a variety of ways: APIs, FTP file transfers, manually by Operations, etc.
- There are different forms of data if viewing it over the axis of time. For example, some data is a snapshot of the latest state. Some data has all the changes over time and require a transformation to view the latest state of the data. Sometimes we receive updates only.
- Most of our data is stored in Google Cloud Storage (GCS) and PostgreSQL. We additionally store caches of data in Elasticsearch for searches.
Who uses our data
Once our data is ingested, it is primarily incorporated into our different offerings by product engineering teams. For example, our SOS business registration data is used in our core product by organizing registrations into groupings we call identities, and matching customer business requests to our identities. Additionally, the consumers of our data are growing as we expand our team - mainly for data science purposes and analysis purposes.
- Incorporated into our product lines by engineering
- Used by data science for modeling, whose use is eventually made into a product (for example, True Industry)
- Analyzed internally in order to derive insights to make product and operational decisions
Recommended data transformation solution
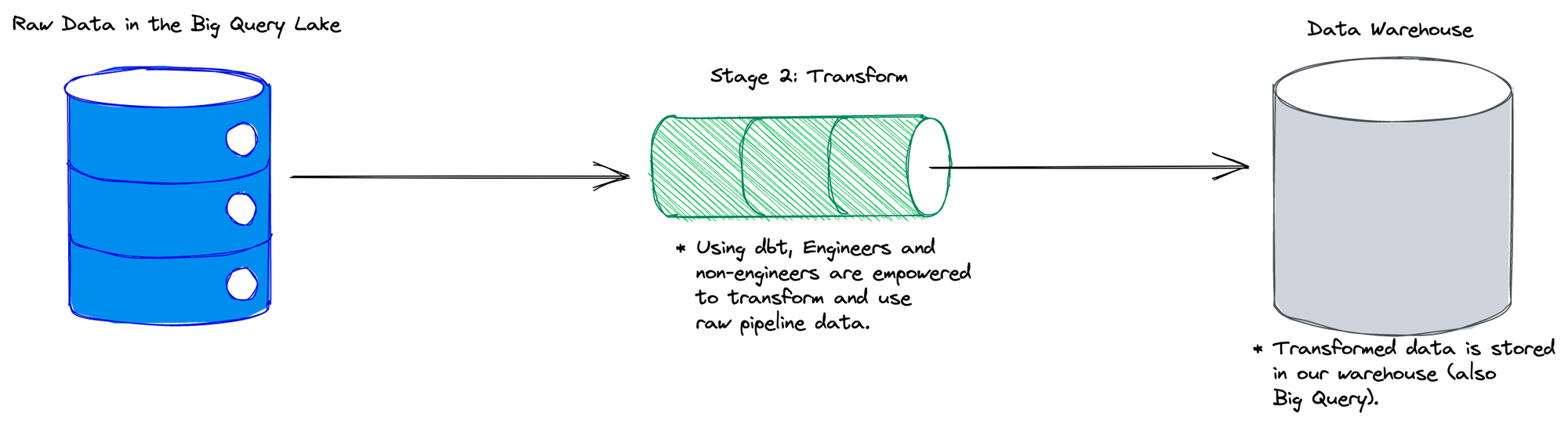
We see opportunity to improve data transformation, which is the process of adapting raw data we extract and load into a canonical format. Transformation kicks off after Stage 1, Extract and Load, processes raw data stored in our data lake by that stage, and stores its output in our warehouse. We have an array of proprietary transformation programs written in Python (we use the Scio library), and orchestrated via Dataflow. This makes it hard to reason about data transformation holistically, and limits the number of people who can make changes to or add data transformations; product engineering teams, the product operation team, and the data science team - use transformed data to do their jobs and build our products.
Data transformation options considered
ETL tools can be homegrown, an open-source tool, or a paid cloud-managed solution. You can also use one big tool for everything, or use specific tools with specific goals. There is also a shift in the industry towards ELT, where data is first loaded, then transformed. Our current system is ELT, where we dump raw data from GCS into BigQuery and then create transformations into aggregate tables that are used to form identities and to search during audits.
Given the familiarity we have with the space, we considered the following transformation tools:
- dbt
- Dataform
We landed on dbt. Why? Transformation of data requires domain knowledge in order for the data to be structured in a way that is useful to be productionized. dbt allows you to create tables of transformed data using SQL, which is what we already do within our Scio pipelines. With dbt, anyone who can write SQL can write transformations using our raw data, which is incredibly powerful and engages so many more of our teammates to leverage data.
Also, the state data we receive is often fragile and changes without warning. If something breaks, a simple SQL adjustment is all that's needed to get our data pipeline back on track. dbt offers version control, testing, code compilation (you can use ifs in SQL), and documentation.
By allowing each team to create transformed data we can develop transformations concurrently without needing to wait for data engineers to finish developing pipelines.
We currently have setup a few of our pipelines running through dbt. It's so much quicker to write SQL transformations in dbt compared to Scio/Dataflow. We've taken the extra time gain and allocated it to adding detailed documentation and testing. I'm confident that this will pay dividends in preventing polluted data from entering our system and detecting quality issues. Win-win.
Post-pipeline actions
For a majority of our pipelines we will push updates to ElasticSearch in order to facilitate quick searches. We achieve this by having append-only tables and indexing net-new rows into ElasticSearch once we transform our data through dbt. The indexing is coordinated as a final step using Airflow.
Quality
- dbt documentation is used to annotate the data.
- dbt tests are used to test the incoming source data (the result of our extract and load) as well as the transformed output data. We use a mixture of the default dbt tests, custom tests, and dbt_expectations which ports a lot of great features from Great Expectations.
- Elementary Data is used to test transformed data for anomaly monitoring over time.
As our team grows, it's important to document and make the knowledge of specific nuances of state data searchable. As we work with at 50 different sets of data for each different data type, engineers who develop pipelines also forget about these nuances and need to read through documentation again to refresh their memories. Using dbt documentation will allow any new member of our organization understand our data without having to ask engineering about the nuances of the data.
dbt tests on both the incoming source data and the outgoing transformed data ensures we don't introduce unexpected or incorrect data downstream. dbt tests are also written in SQL, which makes custom testing very intuitive to write. We have schema tests for key tables, which is something we lost from moving away from Scala with its type system. Elementary Data is good for tracking changes over time and for anomaly detection.
After the RFC: Where we are today
We ended up implementing a solution that allowed for flexibility - we didn't want have to rebuild from end to and end, with a complete migration to get things moving. The strategy was to start with a few pipelines in need of repair:
- Write models to transform our data and set up a job in dbt Cloud that is triggered via API.
- Reuse code to index the data into ElasticSearch as a separate step.
- Move the destination of our existing data pipelines into a different table. Change the original destination to be a view instead of a table, selecting from existing pipeline output as well as from the dbt output. This results in nearly zero disruption, since the original destination now combines the old tables and the new dbt tables.
We plan to move over pipelines one by one as they need maintenance instead of having to coordinate a massive migration. We also will be making improvements to our EL system as well, but also in an incremental way by replacing the above steps with an improved version. This allows for flexibility in balancing technical renovation and innovation, where we gradually improve and harden our system while having room to build a world-class data source to serve as the infrastructure layer for our customers and partners.




